本篇文章记录Deepseek私有化部署以及本地知识库的搭建流程。
1-方案
方案采用ollama+anythingllm+docker私有化部署deepseek-r1:8b。
ollama:大模型的管理和运行工具。
anythingllm:实现文档聊天,本地知识库(支持多个文本检索)的可视化应用。
docker部署anythingllm,实现Web网页访问,非anythingllm官网的桌面访问,是因为Web网页访问的文档聊天更加快速精准以及支持更多个性化设置,如果后续进行接口二次开发,就更要选择docker部署方案。
2-部署
1、前往ollama官网,下载对应系统(window/macos)的应用。
ollama官网:https://ollama.com/
2、ollama安装完成后,打开系统终端,执行下面指令,安装并运行大模型。
ollama run deepseek-r1:8b
建议40系列以上显卡或macos m1芯片性能及以上的运行8b,其余运行7b或以下。
有哪些模型选择可以参考下面ollama官网模型版本选择:
https://ollama.com/library/deepseek-r1
3、运行成功后,可以在终端进行测试。

执行ctrl+D可以退出终端聊天。
4、前往Docker Desktop官网,向下滑动,找到下载即可
Docker Desktop官网:https://www.docker.com/products/docker-desktop/

下载安装Docker Desktop过程中可能存在需要科学上网的情况,否则无法完成登录,搜索远程镜像等操作。
可以参考网上的安装教程:
https://blog.csdn.net/Natsuago/article/details/145588600建议是涉及到Docker Desktop登录或搜索远程镜像等联网操作时,全程进行科学上网,需要科学上网的途径可以使用下面的网址:(完成注册+登录+查看官网教程安装工具,选择并开启代理)
5、Docker Desktop安装完成后,按照如下步骤部署anythingllm
打开系统终端,执行下面指令,查看docker是否安装成功。
docker -v

在系统终端中,执行下面指令,拉取远程镜像mintplexlabs/anythingllm
docker pull mintplexlabs/anythingllm
之后,在终端复制下方对应系统的指令,去运行镜像,建立本地知识库映射。
1 | # Linux/MacOs |
直接运行上面指令后,前往游览器访问http://localhost:3001,现在就可以使用anythingllm了!
你会看到下面的界面:
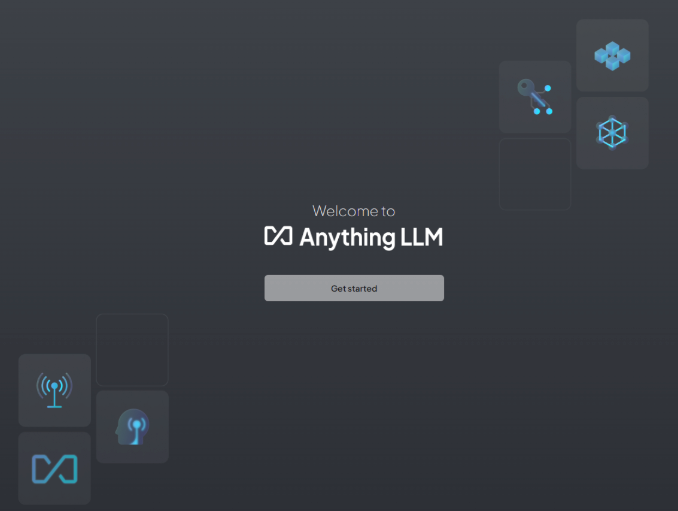
点击开始,进行AnythingLLM配置,选择Ollama,填入 Ollama 的 http://localhost:11434 端口,然后选择下载的deepseek-r1模型,之后一直选择下一步,进入到聊天首页。
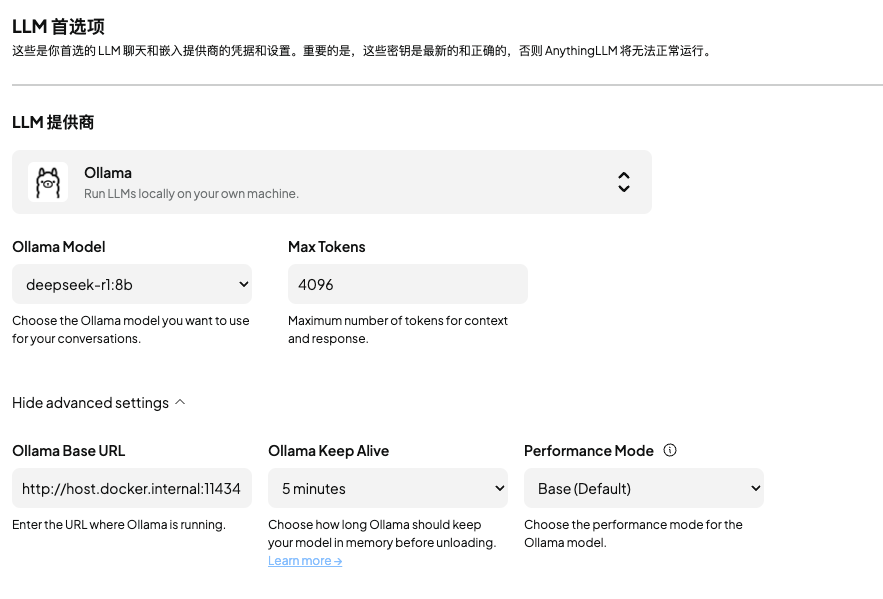
模型配置可以参考:
嵌入引擎配置参考:
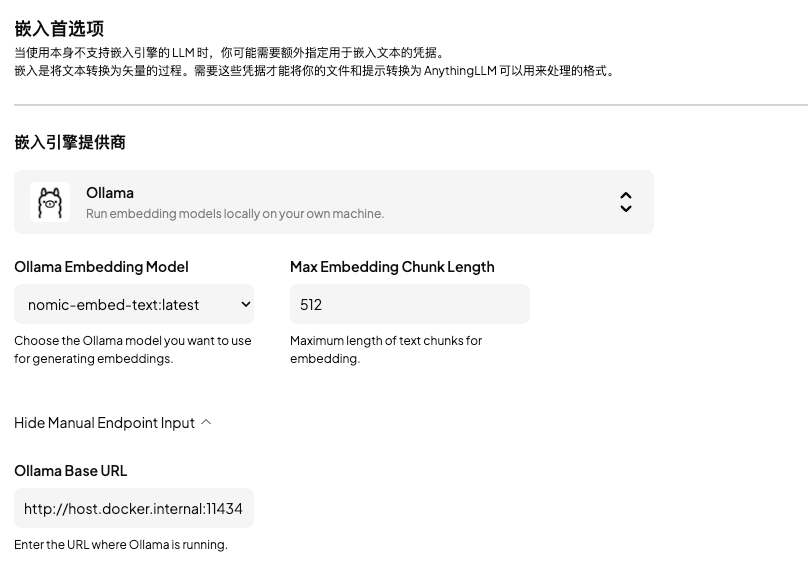
上面嵌入引擎使用了nomic-embed-text模型,需要自行在终端执行下载,用于知识库上传的文件向量化。
ollama模型地址:https://ollama.com/library/nomic-embed-text

6、接下来就可以进行知识库上传,进行聊天/查询
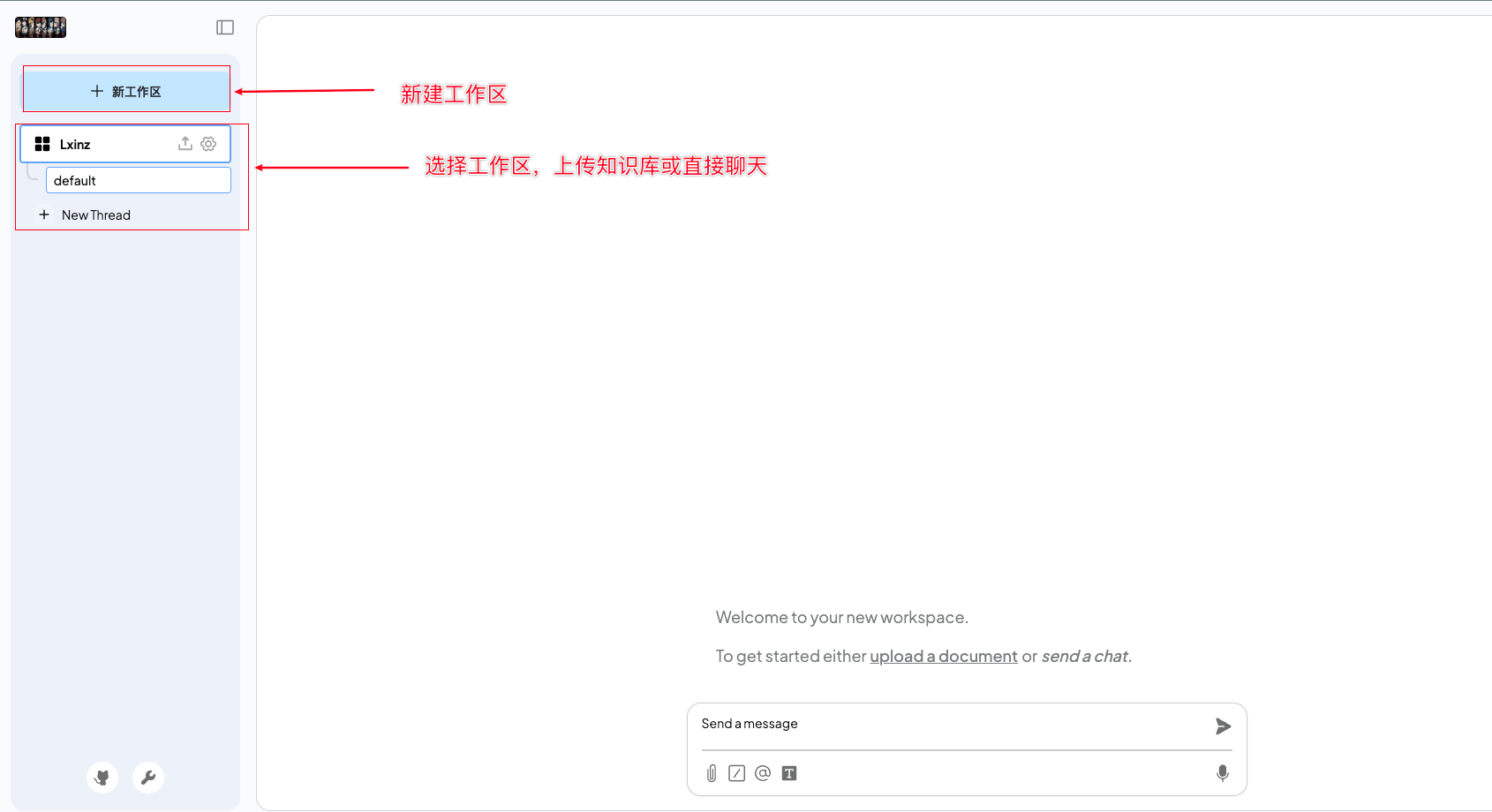
知识库上传后,才可以进行,查询操作,我们需要上传知识库。
<img src="./Deepseek私有化部署/image-20250220104205120.png" alt="image-20250220104205120" style="zoom:50%;" />
选择公共区域的知识移到自己的工作区,并进行知识向量化。
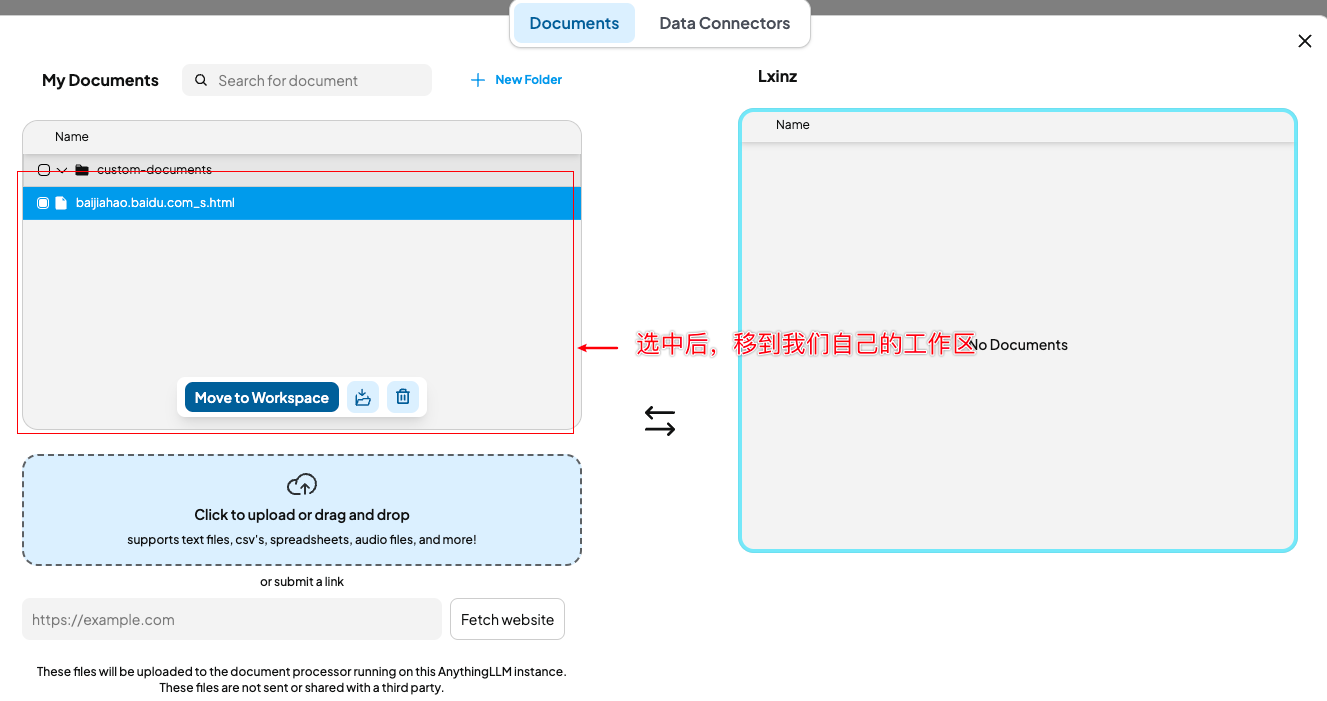
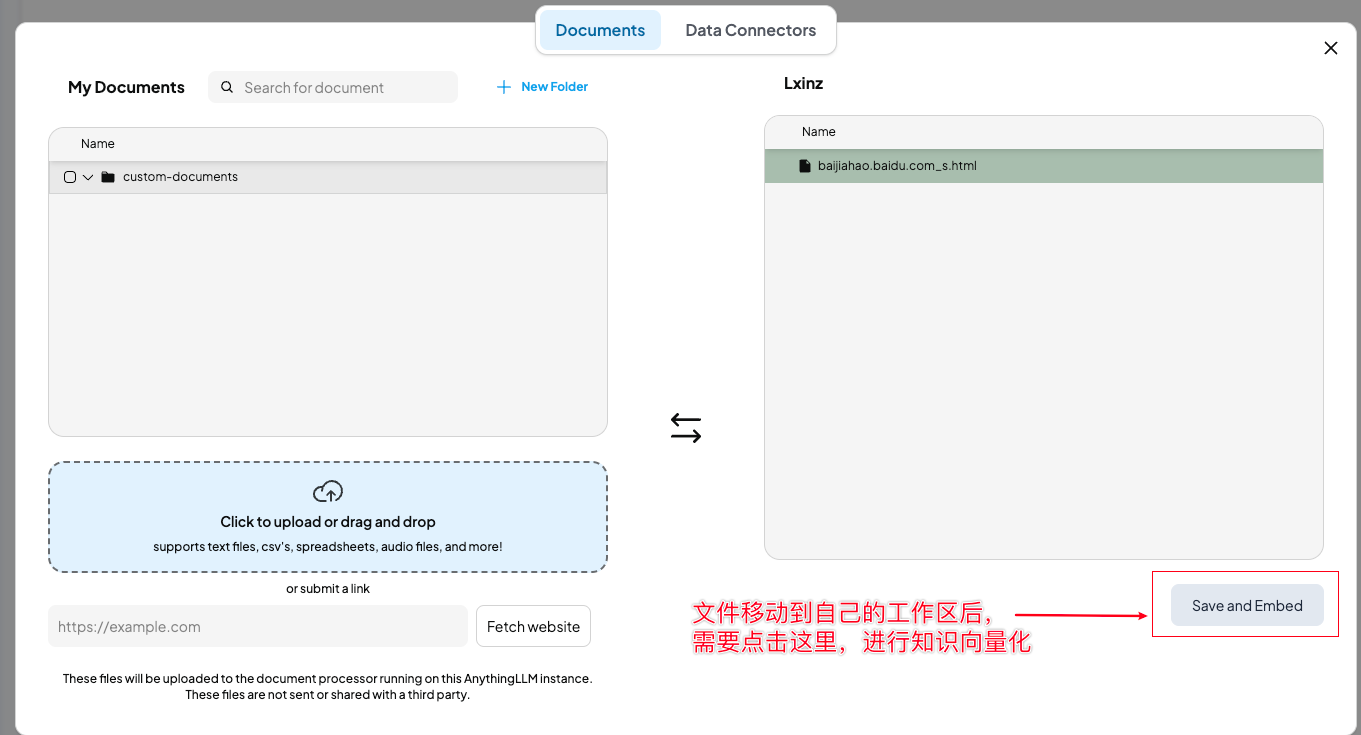
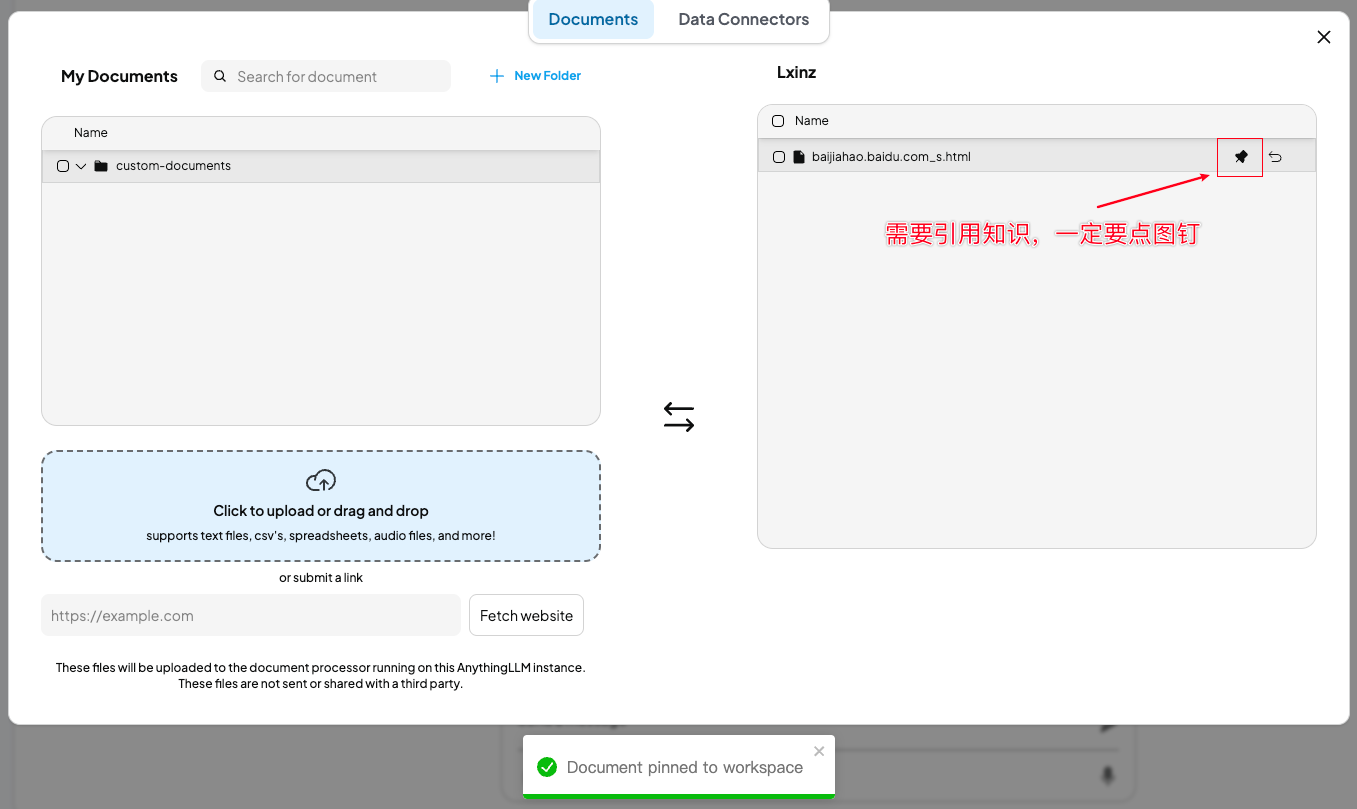
之后,如果在聊天需要引用知识库,则在向量化后,点击图钉。
接下来就可以开始聊天了,比如,我添加了一篇百度文章的知识后,就可以询问它相关知识内容。

7、如果需要个性化定制或api开发,可以在设置中找到。

3-其他知识扩充
1、大模型问答流程图:
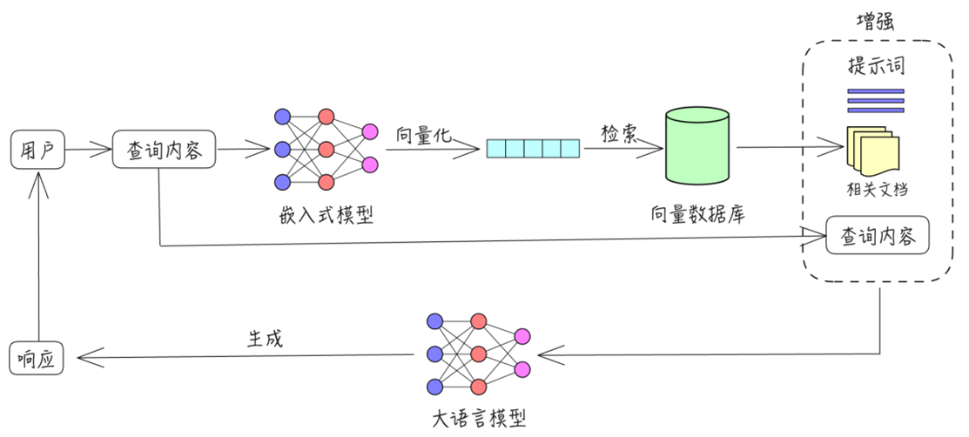
大模型问答基本流程说明:
- 用户查询内容:用户首先输入查询内容,系统将根据用户的请求开始处理。
- 查询内容输入到嵌入式模型:查询内容被送入一个嵌入式模型,该模型将内容进行向量化(或编码)处理,转换成机器可以理解的表示方式。
- 向量化:在嵌入式模型中,查询内容被转化为向量化表示,为下一步的检索提供依据。
- 检索数据库:将向量化后的查询内容与数据库中的大量文档进行匹配,系统从数据库中检索相关的文档或信息。
- 增强提示词:为进一步优化查询效果,系统可以根据检索到的内容生成增强提示词,来进一步引导查询。
- 相关文档返回查询内容:根据生成的增强提示词,系统返回与查询内容最相关的文档或信息,作为最终的响应内容。
- 生成式语言模型:除了检索外,系统还会通过生成式语言模型来生成与查询相关的内容,补充或优化检索到的信息。
- 最终响应:生成式语言模型的输出内容将作为最终的响应返回给用户。
2、大模型 API 接口的速度衡量标准参考:
- RPM (Requests Per Minute):每分钟可以处理的请求数量。
- RPD (Requests Per Day):每天可以处理的请求数量。
- IPM (Images Per Minute):每分钟可以处理的图像数量。
- TPM (Tokens Per Minute):每分钟可以处理的令牌数量。
- TPD (Tokens Per Day):每天可以处理的令牌数量。
- 响应时间:从请求应用端发送到大模型收到响应的时间。